The determinant of a square n×n matrix A is the value that is calculated as the sum of n! terms, half of
them are taken with sign plus, and another half has opposite sign. The determinant of a 2×2 matrix is the area of the parallelogram with the column vectors and as two of its sides. Similarly, the determinant of a 3×3 matrix is the volume of the parallelepiped (skew box) with the column vectors, as three of its edges. When the matrix represents a linear transformation, then the determinant (technically the absolute value of the determinant) is the "volume distortion" experienced by a region after being transformed.
The area of the parallelogram
The volume of the parallelepiped
The Leibniz formula for the determinant of an n × n matrix A is
where sign is the sign function of permutations in the permutation groupSn, which returns +1 and −1 for even and odd permutations, respectively.
Here the sum is computed over all permutations σ of the set {1, 2, …, n}.
A permutation is a function that reorders this set of integers. The value in
the i-th position after the reordering σ is denoted by σi.
The Laplace expansion, named after Pierre-Simon Laplace, also called cofactor expansion, is an expression for the determinant |A| of an n × n matrix A. It is a weighted sum of the determinants of n sub-matrices of A, each of size (n−1) × (n−1).
The Laplace expansion as well as the
Leibniz formula, are of theoretical interest as one of several ways to
view the determinant, but not for practical use in determinant computation. Therefore, we do not pursue these expansions in detail.
If A is a square matrix, then the minor of the entry in the i-th row and j-th column (also called the (i, j) minor, or a first minor) is the determinant of the submatrix formed by deleting the i-th row and j-th column. This number is often denoted Mi,j. The (i, j) cofactor is obtained by multiplying the minor by (−1)i+j.
If we denote by Cij = (−)i+jMi,j the cofactor of the (i, j) entry of matrix \( {\bf A} = \left[ a_{i,j} \right] , \) then Laplace's expansion can be written as
The concept of a determinant actually appeared nearly two millennium before its supposed
invention by the Japanese mathematician Seki Kowa (1642--1708) in 1683, or his German contemporary Gottfried Leibniz (1646--1716). Traditionally, the determinant of a square matrix is
denoted by det(A), det A, or |A|.
In the case of a 2 × 2 matrix (2 rows and 2 columns) A, the determinant is
Each determinant of a 2 × 2 matrix in
this equation is called a "minor" of the matrix A.
It may look complicated, but there is a pattern:
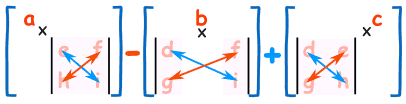
To work out the determinant of a 3×3 matrix:
Multiply a by the determinant of the 2×2 matrix that is not in a's row or column.
Likewise for b, and for c
Sum them up, but remember the minus in front of the b
A similar
procedure can be used to find the determinant of a 4 × 4 matrix, the
determinant of a 5 × 5 matrix, and so forth, where "minors" are the (n-1) × (n-1) matrices that compose the given n×n matrix.
In Python, the command det(M) gives the
determinant of the square matrix M:
Let \( {\bf A} = \left[ a_{i,j} \right] \) be n×n matrix with cofactors \( C_{ij} = (-1)^{i+j} {\bf M}_{i,j} , \ i,j = 1,2, \ldots , n . \)
The matrix formed by all of the cofactors is called the cofactor matrix (also called the matrix of cofactors or, sometimes, comatrix):
\[
{\bf C} = \begin{bmatrix}
C_{11} & C_{12} & \cdots & C_{1n} \\
C_{21} & C_{22} & \cdots & C_{2n} \\
\vdots & \vdost & \ddots & \vdots \\
C_{n1} & C_{n2} & \cdots & C_{nn}
\end{bmatrix}
Then the inverse of A is the transpose of the cofactor matrix times the reciprocal of the determinant of A:
\begin{equation} \label{EqDet.3}
{\bf A}^{-1} = \frac{1}{\det ({\bf A})} \, {\bf C}^{\textrm T} .
\end{equation}
The transpose of the cofactor matrix is called the adjugate matrix of A.
An n × n square matrix A is called
invertible if there exists an n × n
matrix B such that
where I is the identity matrix and the multiplication used is ordinary matrix multiplication. If this is the case, then the matrix
B is uniquely determined by
A and is called the inverse of A, denoted by \( {\bf A}^{-1} . \) If det(A) ≠ 0, then matrix is invertible. A square matrix that is its own inverse, i.e.
\( {\bf A} = {\bf A}^{-1} \) and \( {\bf A}^{2} = {\bf I}, \) is called an
involution or involutory matrix.
We list the main properties of determinants:
1. \( \det ({\bf I} ) = 1 ,\) where I is the identity matrix (all entries are zeroes except diagonal terms, which all are ones).
2. \( \det \left( {\bf A}^{\mathrm T} \right) = \det \left( {\bf A} \right) . \)
3. \( \det \left( {\bf A}^{-1} \right) = 1/\det \left( {\bf A} \right) = \left( \det {\bf A} \right)^{-1} . \)
4. \( \det \left( {\bf A}\, \ast\, {\bf B} \right) = \det {\bf A} \, \det {\bf B} . \)
5. \( \det \left( c\,{\bf A} \right) = c^n \,\det \left( {\bf A} \right) \) for \( n\times n \) matrix
A and a scalar c.
6. If \( {\bf A} = [a_{i,j}] \) is a triangular matrix, i.e. \( a_{i,j} = 0 \) whenever i > j or, alternatively, whenever i < j, then its determinant equals the product of the diagonal entries:
Its inverse is \( {\bf B}^{-1} = -{\bf B} =
\begin{bmatrix} 0&-1 \\ 1&\phantom{-}0 \end{bmatrix} . \)
Its second power \( {\bf B}\,{\bf B} = {\bf B}^2 = -
\begin{bmatrix} 1 & 0 \\ 0 & 1 \end{bmatrix} = -{\bf I} =
\begin{bmatrix} -1 & \phantom{-}0 \\ \phantom{-}0 & -1 \end{bmatrix} \) is
the negative identity matrix.
Next, we calculate its third power
\( {\bf B}\,{\bf B}\,{\bf B} = {\bf B}^3 = - {\bf B} ,
\) and finally the fourth power of the matrix B,
which is the identity matrix:
\( {\bf B}^4 = {\bf I} . \)
▣
A matrix A is called singular if and only if its
determinant is zero. Otherwise, the matrix is nonsingular or
invertible (because an inverse matrix exists for such matrix).
The Cayley--Hamilton method for a 2 × 2 matrix gives
Theorem:
For a square matrix A, the homogeneous equation Ax = 0 has a nontrivial solution (meaning not zero) if and only if the matrix A is singular, so its determinant must be zero.
If A is an invertible square matrix (its determinant is not zero), then we can multiply both sides of the equation Ax = 0 by the inverse matrix A−1 to obtain
A square matrix whose transpose is equal to its inverse is called an
orthogonal matrix;
that is, A is orthogonal if \( {\bf A}^{\mathrm T} = {\bf A}^{-1} . \)
Example 3:
In three-dimensional space, consider the rotational matrix
Yandl, A.L. and Swenson, C., A class of matrices with zero determinant, Mathematics Magazine, 2012, Vol. 85, Issue 2, pp. 126--130. https://doi.org/10.4169/math.mag.85.2.126