Eigenvalues and Eigenvectors
The eigenvalues and corresponding eigenvectors of a matrix
![]() are determined by solving
are determined by solving
![\begin{displaymath}{\bf I} = \left [ \begin{array}{cccccccc}
\par 1 & & \\
& 1 ...
...ge0} \\
{\Large0} & & & \ddots\\
& & & & 1
\end{array}\right]\end{displaymath}](img3.gif)
![\begin{displaymath}W= \left [ \begin{array}{ccccccccccc}
1\\
&2 & \\
& & 3 & &...
... & & & \ddots\\
& & & & 19\\
& & & & & 20
\end{array}\right ]\end{displaymath}](img10.gif)
Next, we provide some basic background on linear algebra.
First, we define the similarity transformation.
Specifically, we say that the matrix ![]() is similar
to matrix
is similar
to matrix ![]() if
if ![]() and
and ![]() have the same eigenvalues (i.e. the same eigenspectrum)
but not necessarily the same eigenvectors. Therefore, the transformation
have the same eigenvalues (i.e. the same eigenspectrum)
but not necessarily the same eigenvectors. Therefore, the transformation
Remark 1: The transpose matrix ![]() is similar to matrix
is similar to matrix ![]() since they have the same
characteristic polynomial. However, they do not have the same eigenvectors.
In contrast, the inverse matrix
since they have the same
characteristic polynomial. However, they do not have the same eigenvectors.
In contrast, the inverse matrix
![]() has the same
eigenvectors with
has the same
eigenvectors with ![]() but inverse eigenvalues,
but inverse eigenvalues,
![]() .
This is true because
.
This is true because
Remark 2: The matrix
![]() ,
where k is a positive integer has eigenvalues
,
where k is a positive integer has eigenvalues ![]() ,
where
,
where ![]() are the eigenvalues of
are the eigenvalues of ![]() .
However,
.
However,
![]() and
and ![]() have the same eigenvectors.
This can be extended further and it is easy to show
that if we construct a polynomial matrix:
have the same eigenvectors.
This can be extended further and it is easy to show
that if we construct a polynomial matrix:
We have already seen that computing the eigenvalues accurately from
the determinant may not always be possible, although the
Newton-Raphson method of chapter ![]() is an accurate method of computing the roots of polynomials but it may be
inefficient. In the following, we present a simple method
to compute iteratively and selectively the maximum and minimum eigenvalues
and corresponding eigenvectors.
is an accurate method of computing the roots of polynomials but it may be
inefficient. In the following, we present a simple method
to compute iteratively and selectively the maximum and minimum eigenvalues
and corresponding eigenvectors.
Power Method
This is a very simple method to obtain the maximum eigenvalue.
The main idea is to obtain iterates from
To see why this process converges and at what rate we
project the initial guess ![]() to the space
spanned by all the eigenvector
to the space
spanned by all the eigenvector ![]() of
of ![]() ,
i.e.,
,
i.e.,
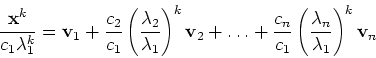
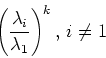
The convergence rate is determined by the
relative convergence of the second largest to the largest term, i.e.,
the ratio
A pseudo-code for this algorithm is:
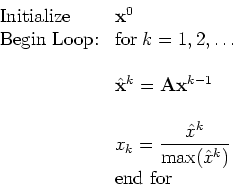
In the algorithm above the value of ![]() is
estimated from the maximum component of
is
estimated from the maximum component of
![]() However, any other norm can be used, e.g., the L2 norm
However, any other norm can be used, e.g., the L2 norm
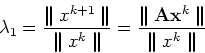
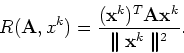
![\begin{eqnarray*}R({\bf A}, x) & = & \frac{{\bf x}^T {\bf A}{\bf x}}{{\bf x}^T{\...
...right )^2 +
\ldots + \left (\frac{c_n}{c_1}\right )^2}\right ].
\end{eqnarray*}](img70.gif)
The convergence of the power method can be enhanced
by shifting the eigenvalues,
so instead of multiplying the initial guess by powers of ![]() we multiply by powers of
we multiply by powers of
![]() which has
eigenvalues
which has
eigenvalues
![]() while the eigenvectors remain the same.
The corresponding convergence rate is then estimated by
while the eigenvectors remain the same.
The corresponding convergence rate is then estimated by
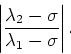
The Inverse Shifted Power Method
In order to compute selectively the smallest eigenvalue
we can apply again the power method by multiplying by
powers of the inverse, i.e.,
![]() Thus, the iteration procedure here is
Thus, the iteration procedure here is
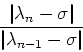
The following pseudo-code summarizes the algorithm:
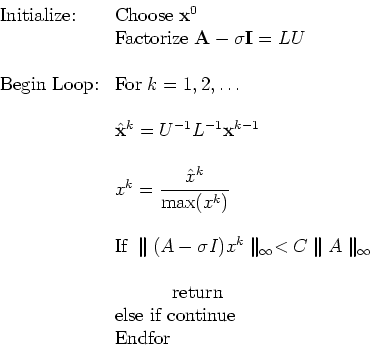
Remark 1: Note that we do not actually compute
explicitly the inverse
![]() or
or
![]() but we simply do an LU factorization only once outside the loop.
So the computational complexity of this algorithm is
but we simply do an LU factorization only once outside the loop.
So the computational complexity of this algorithm is
![]() times the number of iterations plus the initial
times the number of iterations plus the initial
![]() cost for
the LU factorization.
cost for
the LU factorization.
Remark 2: To accelerate convergence, we can start with
a few iterations using the standard power method, obtain a first good guess
and corresponding shift ![]() via the Rayleigh quotient,
and then switch to the inverse iteration method.
via the Rayleigh quotient,
and then switch to the inverse iteration method.
Remark 3: The matrix
![]() is ill-conditioned, however in practice the error associated
with this seems to favor the inverse iteration as it grows toward
the direction of the desired eigenvector. Therefore, the inverse shifted power
method is a stable method.
is ill-conditioned, however in practice the error associated
with this seems to favor the inverse iteration as it grows toward
the direction of the desired eigenvector. Therefore, the inverse shifted power
method is a stable method.
We can modify the inverse shifted power method and
enhance convergence even more (to third-order) if we update the
value of the shift adaptively using the Rayleigh quotient.
The following algorithm presents this modification :
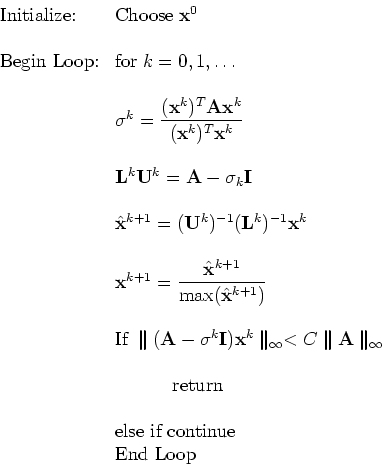
Remark: While this algorithm triples
the number of correct digits in each iteration
it requires
![]() work at each iteration
because the matrix
work at each iteration
because the matrix
![]() changes in each iteration.
A more economical approach is to ``freeze''
changes in each iteration.
A more economical approach is to ``freeze'' ![]() for a
few iterations so that the LU decomposition is not employed in each iteration.
The resulted convergence rate is then less than cubic but overall this is
a more efficient approach.
for a
few iterations so that the LU decomposition is not employed in each iteration.
The resulted convergence rate is then less than cubic but overall this is
a more efficient approach.