The Lanczos Eigensolver
This algorithm, developed by Lanczos in the 1950s, is particularly useful for large symmetric matrices, which are sparse. The QR method can also be used for such systems but it does not maintain the sparsity of the new matrices in each iteration and thus it becomes inefficient.
The key idea in Lanczos's approach is to make use of all the previous iterates
Assuming that we have produced the orthonormal vectors
We can then transform ![]() to its similar matrix
to its similar matrix ![]() suing the similarity transformation, ie.
suing the similarity transformation, ie.
![\begin{displaymath}T_k = \left [ \begin{array}{ccccccccccccc}
& & \alpha_1 && \...
... &&& \beta_{ky} & &\alpha_k & &\beta_{k-1}\end{array}\right ].
\end{displaymath}](img12.gif)
We can compute now the coefficients ![]() and
and ![]() from the orthonormality conditions.
First multiplying the above equation by
from the orthonormality conditions.
First multiplying the above equation by
![]() we obtain
we obtain
The coefficient ![]() is also obtained from the recurrence formula
is also obtained from the recurrence formula
All vector
![]() generated by the 3-term sequence are
orthogonal to all
generated by the 3-term sequence are
orthogonal to all ![]() ,
k< i given the symmetry of
the matrix
,
k< i given the symmetry of
the matrix ![]() .
This can be proved by induction.
First, we assume that
.
This can be proved by induction.
First, we assume that
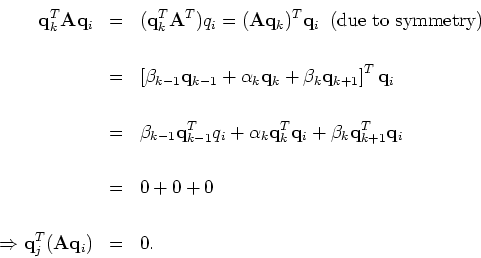
In practice, the problem is that the orthogonality is not preserved.
In fact, as soon as one eigenvalue converges all the basis
vectors ![]() pick up perturbations biased toward the direction
of the corresponding eigenvector and orthogonality is lost.
This has been analyzed in detail by Paige [#!Paige!#]
who found that a ``ghost'' copy of the eigenvalue
will appear again in the tridiagonal matrix
pick up perturbations biased toward the direction
of the corresponding eigenvector and orthogonality is lost.
This has been analyzed in detail by Paige [#!Paige!#]
who found that a ``ghost'' copy of the eigenvalue
will appear again in the tridiagonal matrix ![]() The straightforward remedy is to fully re-orhonormalize
the sequence by using Gram-Schmidt or even QR. However, either
approach would be expense if the dimension if the Krylov space is large,
so instead a selective re-orthonormalization is pursued.
More specifically, the practical approach is to orthonormalize
half-way i.e., within half machine-recision
The straightforward remedy is to fully re-orhonormalize
the sequence by using Gram-Schmidt or even QR. However, either
approach would be expense if the dimension if the Krylov space is large,
so instead a selective re-orthonormalization is pursued.
More specifically, the practical approach is to orthonormalize
half-way i.e., within half machine-recision
![]() [#!Templates2!#].
[#!Templates2!#].
The following algorithm presents an orthogonalized version of the basic Lanczos algorithm for symmetric matrices.
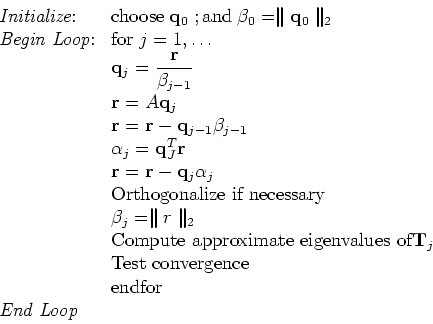
Remark 1: If the eigenvalues of ![]() are
not well separated, then we can use a shift and employ the matrix
are
not well separated, then we can use a shift and employ the matrix
Remark 2: The Lanczos algorithm can be extended to non-symmetric systems - see references in [#!Saad!#], [#!Templates!#].